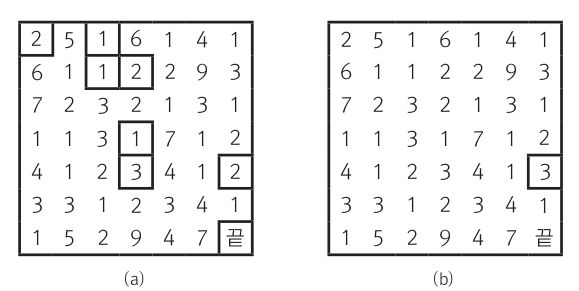
// BOGGLEGAME_2
#include <iostream>
#include <string.h>
static const int BOGGLE_MAX = 5;
static const int WORD_MAX = 10;
int g_ArrX[] = { -1, 0, 1, 1, 1, 0, -1, -1 };
int g_ArrY[] = { -1, -1, -1, 0, 1, 1, 1, 0 };
char* g_Boggle[BOGGLE_MAX];
char* g_WordsArr[WORD_MAX];
// 기록 배열
char g_CacheArr[BOGGLE_MAX][BOGGLE_MAX][WORD_MAX] = {0,};
int g_StringLen = 0;
int g_CurCharNum = 0;
int g_CurWordNum = 0;
// 해당 좌표에 전달되는 문자가 있는지 검사
bool f(int y, int x, char CurChar)
{
// 기저사례 1 x또는 y가 범위 밖이라면 false
if (x < 0 || y < 0)
return false;
// 기저사례 1 x또는 y가 범위 밖이라면 false
if (x >= BOGGLE_MAX || y >= BOGGLE_MAX)
return false;
// 기저사례 2 찾으려는 문자가 '\0' 이거나
// 문자열의 길이와 같으면 문자열을 찾은것이므로 true
if (CurChar == '\0' || g_CurCharNum > g_StringLen)
return true;
// 찾으려고 하는 좌표가 이미 -1 이라면 여긴 이전에 찾았던 곳이므로 패스
if (g_CacheArr[y][x][g_CurCharNum] == -1)
return false;
if (g_Boggle[y][x] == CurChar)
{
if (g_StringLen == 1){
// 기저사례 3 문자를 찾았는데 문자열의
// 길이가 1이면 곧 찾는 문자열이므로 true
return true;
}
// 문자를 찾았으면 문자인덱스를 1증가
++g_CurCharNum;
// 현 인덱스를 중심으로 다음 문자를 8방향 검사
for (int i = 0; i < 8; i++)
{
// 모두 찾으면 true
if (f(
(y + g_ArrY[i]), // y좌표
(x + g_ArrX[i]), // x좌표
g_WordsArr[g_CurWordNum][g_CurCharNum])
)
{
return true;
}
}
// 문자를 못찾았으면 문자인덱스 1감소
--g_CurCharNum;
// 8방향 모두 아니라면 현재 좌표에서 다음문자를 찾을 방법이 없기때문에 -1
g_CacheArr[y][x][g_CurCharNum] = -1;
}
// 현 인덱스의 문자가 찾는 문자가 아니면 false
return false;
}
int main()
{
// 테스트 케이스
int testCase = 0;
int stringCount = 0;
int temp = 0;
for (int i = 0; i < BOGGLE_MAX; i++)
{
g_Boggle[i] = new char[BOGGLE_MAX + 1]();
}
for (int i = 0; i < WORD_MAX; i++)
{
g_WordsArr[i] = new char[WORD_MAX + 1]();
}
scanf("%d", &testCase);
while (testCase--){
g_CurWordNum = 0;
// 보글게임판 5 x 5 입력
for (int i = 0; i < BOGGLE_MAX; i++)
{
scanf("%s", g_Boggle[i]);
}
// 확인하려는 문자열 갯수 입력
scanf("%d", &stringCount);
temp = stringCount;
// 확인하려는 문자열 입력 ENTER 구분
for (int i = 0; i < stringCount; i++)
{
scanf("%s", g_WordsArr[i]);
}
while (stringCount--){
bool isYes = false;
// 단어를 찾는 루프를 돌 때마다 캐시를 -1로 초기화해준다.
memset(g_CacheArr, 0, sizeof(g_CacheArr));
// 현재 검사하려고 하는 문자열의 길이 저장
g_StringLen = (int)strlen((const char*)g_WordsArr[g_CurWordNum]);
// g_CurCharNum = 현재 검사하려고하는 문자 인덱스 예) ABCDE에서 C 면 2
g_CurCharNum = 0;
for (int y = 0; y < BOGGLE_MAX; y++)
{
for (int x = 0; x < BOGGLE_MAX; x++)
{
// y, x인덱스와 찾으려는 문자열의 문자를 f에 넘김
// 있으면 YES
if (
f(y,
x,
g_WordsArr[g_CurWordNum][g_CurCharNum]))
{
printf("%s YES\n", g_WordsArr[g_CurWordNum++]);
isYes = true; // 루프를 빠져나간다.
break; // 루프를 빠져나간다.
}
}
if (isYes) // 루프를 빠져나간다..
break; // 루프를 빠져나간다..
}
// 4, 4까지 돌았는데 없으면 NO
if (!isYes)
{
printf("%s NO\n", g_WordsArr[g_CurWordNum++]);
}
}
}
// 메모리 해제
for (int i = 0; i < BOGGLE_MAX; i++)
{
delete []g_Boggle[i];
g_Boggle[i] = NULL;
}
for (int i = 0; i < WORD_MAX; i++)
{
delete[]g_WordsArr[i];
g_WordsArr[i] = NULL;
}
return 0;
}