4주간 논산 육군 훈련소를 가게되었다.
한달정도 글을 쓰지 못한다.
아직도 써야할 포스트 목록이 산더미다.
다녀와서 천천히 써야지.
'All > ETC' 카테고리의 다른 글
| 국토종주 (0) | 2017.05.10 |
|---|---|
| 유용한 사이트 (0) | 2016.11.28 |
| Tistory Start (0) | 2015.12.28 |
4주간 논산 육군 훈련소를 가게되었다.
한달정도 글을 쓰지 못한다.
아직도 써야할 포스트 목록이 산더미다.
다녀와서 천천히 써야지.
| 국토종주 (0) | 2017.05.10 |
|---|---|
| 유용한 사이트 (0) | 2016.11.28 |
| Tistory Start (0) | 2015.12.28 |
이전 포스트를 이어서 퀵정렬의 pivot을 설정하는 방법에 대해 이야기 하도록 하겠다.
먼저 퀵정렬이 빠른 이유에 대해 알아야 한다.
전제 조건은 랜덤하게 정렬된 배열을 퀵정렬 알고리즘으로 정렬하는 것으로 한다.
퀵정렬의 구동 원리를 자세히 생각해보면 퀵정렬이 빠른 이유를 알 수 있다.
구동원리는 다음과 같다.
1. 피벗을 설정한다.
2. 피벗보다 큰 수는 오른쪽 작은 수는 왼쪽에 배치한다.
3. 피벗을 기준으로 두개의 배열로 나눈다.
4. 각각의 배열을 1번부터 재귀적으로 반복한다.
만약 위의 방법만으로 정렬이 되는 것을 믿지 못하겠다면 [ 10. QuickSort ] 포스트를 참조하여 직접 따라가면서 컴파일 해보는 것을 추천한다.
힌트를 주자면 위의 단계처럼 두개의 배열로 나누다 보면 언젠가 하나의 배열이 3개 혹은 2개 혹은 1개가 되는데
상식적으로 생각해보면 3개중 하나의 요소를 기준으로 좌우로 정렬한다면 오름차순으로 정렬될 수 밖에 없다는 것을 생각해보기 바란다.
다시 돌아와서 내가 생각한 퀵정렬이 빠른 가장 큰 이유는 바로 먼 거리 처리 능력 이다.
다음과 같은 두개의 배열을 두 가지 방법으로 정렬한다고 가정하자.
[2, 3, 4, 5, 6, 7, 8, … N, 1] => 1과 N, 1과 (N - 1), 1과 (N - 2), 1과 (N - 3), ... 1과 (N - (N - 1)) 비교 후 제자리를 찾음 (총 N - 1번 비교)
[2, 3, 4, 5, 6, 7, 8, … N, 1] => 1과 2를 비교 후 작다면 1앞에 배치 (1번 비교)
( 극단적인 상황이지만 먼거리 처리 능력을 보여주는 좋은 예 인것 같다. )
정렬 알고리즘의 수행시간을 결정짓는 모든 근원은 비교연산의 횟수와 교환연산의 횟수이다.
그리고 똑같은 코드를 얼마나 반복하는지이다.
(상식적으로 for문을 아무런 처리 없이 n^2 번 반복시킨다고 해도 그렇게 오랜시간이 걸리지 않는다.)
결국 빠른 알고리즘은 코드를 얼마나 적게 수행하는 지에 따라 결정된다.
코드를 적게 수행하는 방법은 비교연산을 통해 코드를 스킵하는 것이다.
이 모든 것이 비교를 하는 방법에 따라 결정되며 곧 먼거리를 한번에 이동할 수 있는 알고리즘이냐 아니냐의 문제라고 생각한다.
기존 알고리즘의 문제점
그렇다면 퀵정렬의 먼거리 처리능력이 소용없어지게 된다면 퀵정렬이 느려질까?
퀵정렬의 먼거리 처리 능력을 없애는 방법은 이미 정렬된 배열을 정렬 시키거나 역순으로 정렬된 배열을 정렬시키는 것이다.
위 두가지의 경우 퀵정렬 역시 순차적으로 모두 비교를 하게 되기 때문이다.
그 이유는 앞서 구현하였던 퀵정렬이 피봇을 선택하는 방법에서 찾을 수 있다.
무조건 left의 값을 피봇으로 설정 하기 때문에 피봇이 항상 가장 크거나 가장 작은 값이된다.
때문에 모든 요소와 비교를 하며 먼거리 처리능력도 소용이 없게 된다.
실제로 앞선 [ 10. QuickSort ]의 알고리즘으로 역순 배열이나 정렬된 배열을 정렬하면 n^2의 시간이 걸린다.
해결방안
어떻게 하면 퀵정렬이 랜덤인 상황이 아니더라도 빠른속도를 유지 할 수 있을까?
사실 이부분에서 나는 굉장히 많은 시간을 보냈다. 알고리즘을 새로운 방법으로 짜보기도 하는 등 여러가지 시도를 해보았다.
여러가지 시도를 하면서 중점을 맞춘 내용은 어떤 상황이더라도 Pivot을 기준으로 최대한 동등하게 배열을 나누는 것 이었다.
생각하기까지 매우 오랜시간이 걸렸지만 결과적으로는 매우 간단하게 해결할 수 있었다.
바로 배열의 가운데값을 피봇으로 설정하는 것이다.
물론 실제 가운데 값을 피봇으로 설정한 후 알고리즘을 실행시키면 제대로 정렬되지않을 뿐더러 데이터가 엉망이된다.
그래서 조금만 비껴생각해낸 것이 배열의 가운데 값을 left값과 교환하는 것이다. 그 이후의 방법은 기존알고리즘과 동일하다.
바뀐 코드는 아래와 같다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | // QUICKSORT_ver2 // Swap 함수 - 두 요소를 교환한다. void swap(int& num1, int& num2) { int temp = num1; num1 = num2; num2 = temp; } void q_sort(int numbers[], int left, int right) { int pivot, l_hold, r_hold, median; l_hold = left; r_hold = right; // pivot설정 방법 변경 (성능UP) median = (left + right) / 2; swap(numbers[left], numbers[median]); | cs |
이 아래로는 이전의 코드와 동일하다.
핵심적인 부분은 바로 median을 설정하는 부분과 그것을 left(원래의 피벗)과 교환하는 부분이다.
median을 배열의 가운데 요소로 선택하고 이것을 다시 피벗과 교환함으로써 피벗이 가장 큰값이나 작은 값이 아닌 중간값으로 설정된다.
때문에 오름차순이나 내림차순으로 미리 정렬된 배열의 경우에도 동등한 2개의 배열을 만들어 낼수 있으며
이는 곧 퀵정렬의 강점을 살릴 수 있게 된다는 것이다.
위의 코드를 이용하여 실제로 테스트를 해본 결과는 아래와 같다.
기존의 알고리즘
요소 수 : 100,000 100,000,000
랜덤 배열 : 0.017 23
역순 배열 : 12.89 너무 오래걸려서 측정 불가
순열 배열 : 13.21 너무 오래걸려서 측정 불가
Median피벗 알고리즘
요소 수 : 100,000 100,000,000
랜덤 배열 : 0.017 23
역순 배열 : 0.0076 8.98
순열 배열 : 0.0072 8.46
이전 알고리즘에 비해서 매우 빠른 속도를 보여준다.
| 자동적에이전트 - Arrive (0) | 2016.02.22 |
|---|---|
| 자동적에이전트 - Flee (0) | 2016.02.21 |
| 자동적에이전트 - Seek (0) | 2016.01.17 |
| QuickSort (0) | 2016.01.07 |
| ShellSort (0) | 2016.01.05 |
자동적 에이전트 (Autonomous Agent)란?
자동으로 움직이며(행동하며) 현재 혹은 미래의 상황을 감지하고 그에 따른 적절한 반응을 보여주는 AI객체라고 생각한다.
AI 프로그래머가 디자인 하기에 따라 무엇을 찾는 다거나 무엇으로 부터 숨는다거나, 집단적인 행동을 한다거나 독자적으로 배회하는 등의 행동을 할 수 있다.
앞으로의 포스트에서 여러가지 행동으로 디자인된 에이전트들의 모습과 구현 방법에 대해 이야기 하겠다.
본 내용은 "실용적 예제로 본 게임 인공지능 프로그램하기"라는 책을 읽은 후 배운 내용을 바탕으로 정리하는 것이다.
Seek - 찾기
가장 먼저 이야기할 행동은 목표 타겟을 찾는 행동인 Seek이다.
결과를 먼저 보자면 위의 그림처럼 진행하던 방향에서 목표지점을 향해 점차적으로 방향을 틀어 이동하는 모습을 볼 수 있다.
원리를 설명하기에 앞서 조종행동에서 중요하게 사용되는 벡터에 대해 설명하겠다.
조종행동에서 빠질 수 없는 것이 바로 벡터(Vector)이다.
벡터는 스칼라와 동일하게 ( X, Y )으로 표현하지만 의미는 매우 다르다.
스칼라 포인트 ( 3 , 3 )의 경우 ( 0, 0 )을 기준으로 하는 좌표계에서 아래와 같은 점으로 표시된다.
하지만 벡터의 경우 ( 0, 0 )을 기준으로 ( 3, 3 )을 표현하면 아래와 같다.
이렇게 화살표로 표현되는 이유는 스칼라는 단순히 좌표 즉, 위치에 대한 정보만 가지고 있지만 벡터의 경우 위치와 방향의 정보를 가지고 있기 때문이다.
때문에 같은 ( 3, 3 )의 정보라도 벡터값인지 스칼라 값인지에 따라 의미하는 것은 다를 수 있다.
간단하게나마 벡터에 대한 설명을 했고 본격적으로 찾기 조종행동에 대해 알아 보겠다.
원리는 다음의 그림과 같다.
첫번째 그림에서 보이듯이 에이전트는 C의 속도(방향)로 이동 중 이었다. 그러던 중 Goal을 찾게 되었고 목표지점으로 설정한 후 도달하길 원하고 있다.
Goal에 도달하기 위한 원하는 속도(T)는 다음의 공식으로 구할 수 있다.
G(Goal) - 현재위치(P) = 원하는 속도(T) => T = G - P
G라는 포인트, 스칼라값에서 P라는 포인트, 스칼라값을 빼면 바로 T라는 벡터를 얻을 수 있다. 스칼라 - 스칼라 = 벡터이기 때문이다.
원하는 속도는 구하였다. 그렇다면 어떻게 C에서 T로 속도를 바꿀 수 있을까?
간단하게는 그냥 현재 P의 속도를 T로 바꿔만 주면 해결될 것이다.
하지만 그렇게 하면 Goal을 향해서 직선으로 이동할 뿐 내가 원하는 느낌인 커브를 도는것을 볼 수 없다.
답은 두번째 그림에서 찾을 수 있다.
바로 조종힘인 D를 구하고 그것을 현재 속도에 점차적으로 더해주면 된다.
조정힘을 구하는 공식은 다음과 같다.
원하는 속도(T) - 현재속도(C) = 조종힘(D) => D = T - C
이제 계산되어 나온 D를 현재 속도에 더해주면 에이전트가 점차적으로 방향을 트는 것을 확인 할 수있다.
코드
1 2 3 4 5 6 7 8 9 | Vector2D SteeringBehaviors::Seek(Vector2D GoalPos){ // TargetVelocity = 원하는 속도 // 원하는 속도 구하는 공식 : T = (G - P) * speed // 순수 방향만 얻기 위해 정규화 후 speed를 곱한다. Vector2D TargetVelocity = Vec2DNormalize(GoalPos - m_pVehicle->Pos()) * m_pVehicle->MaxSpeed(); // return value는 조종힘 // 조종힘 구하는 공식 : D = T - C return (TargetVelocity - m_pVehicle->Velocity()); } | cs |
+ 후에 동영상을 올릴 수 있으면 추가하겠다.
| 자동적에이전트 - Flee (0) | 2016.02.21 |
|---|---|
| 피벗설정에 따른 퀵정렬의 속도 (0) | 2016.01.18 |
| QuickSort (0) | 2016.01.07 |
| ShellSort (0) | 2016.01.05 |
| InsertionSort (0) | 2016.01.03 |
페이스북 SDK 작업을 진행하다가 몇가지 오류를 해결하였다.
1. 세션 오픈 실패
해시키가 페이스북 페이지에 등록되지 않았을 경우 발생할 수 있다.
해시키 뽑는 방법 - 페이스북 페이지에서 KeyTool을 실행시켜서 뽑는다.
( KeyTool에 KeyStore와 프로젝트 패키지 이름을 이용해서 실행시키면 뽑을 수 있다. )
해시키를 뽑으면 페이스북 개발자 페이지에 등록한다.
이후 로그인 가능
2. 페이스북 친구가 안뜸
캔버스 설정이 안되어 있는 경우 친구 목록을 받아 오지 못할 수 있다.
3. 캔버스 설정을 했지만 친구가 안뜸
페이스북에서 보내준 친구ID 값이 string이었다. 20 ~ 30자리를 그냥 long long으로 파싱해서 사용하다보니 변환과정에서 문제가 있었다.
때문에 각 문자의 Ascii값을 모두 더해 ID값으로 대신 사용하였다.
| 구글 결제관련 에러 (42) | 2016.01.15 |
|---|
구글의 결제 모듈을 테스트 하던 중에 몇몇 에러를 만났다.
처음에는 조금 당황했지만 구글의 힘으로 해결하였다.
여기에 정리해 두어야겠다.
1. 구글플레이에 알파로 앱을 등록하고 결제테스트시 "인증이 필요합니다. Google 계정에 로그인해야 합니다."라는 메시지가 출력될 때
다음과 같은 시도를 해보았다.
- PublicKey를 교체했다.
- 알파로 등록한 apk를 "앱게시" 하였다. (이것으로 해결되었다)
- 구글페이지에서 테스터로 등록하였다.(결제 테스트시 라이센서로도 등록해야한다.)
2. 결제 테스트 중 "요청하신 항목은 구매할 수 없습니다." 라는 메시지가 뜸
- 페이지에 등록한 인앱상품을 활성화 시켰다.(이것으로 해결되었다.)
- 등록한 앱 버전보다 높은 버전으로 테스트시 발생할 수 있다.
- 구글 콘솔 페이지에 있는 테스터 참여 링크에 들어가서 확인 버튼을 누르지 않았을때 발생할 수 있다.
- 핸드폰에 여러 구글 계정이 연동되어 있으면 발생할 수 있다.
(구글 플레이 계정 정보에서 현재 연동된 모든 계정을 확인 할 수 있다. 여기서 테스트 계정만 남기고 모두 제거 해야한다.)
아래 사진에서 하얀색 화살표를 누르면 확인할 수 있다.
3. 결제 테스트 중 "Item already owned"라는 로그가 출력되면서 결제가 되지 않는 현상
- 이 문제는 캐시를 결제하고나서 소비하지 않고 다시 결제를 한 경우 발생하는 로그로 소비되지 않는 문제를 해결하니 자동으로 해결되었다.
- 내가 겪었던 소비되지 않는 이유는 PublicKey가 서버와 다르게 적용되어 있었기 때문에 결제 후 제대로 소비되지 않았다.
- 따라서 이를 해결하니 모두 해결되었다.
4. "이 버전의 어플리케이션에서는 GooglePlay를 통한 결제를 사용할 수 없습니다."라는 메시지 출력
- 이클립스에서 Run으로 실행하여 디바이스에 설치한 apk의 경우 위의 메시지를 출력한다.
- export한 apk로 테스트 하니 진행할 수 있었다.
| 페이스북 세션 오픈 실패 오류 (0) | 2016.01.16 |
|---|
평균적으로 가장 빠르다는 QuickSort!!
사실 좀 많이 실망했다. 결과를 먼저 말하자면 랜덤 배열일 경우 shellsort보다 5배 정도 빠르다지만
순열이나 역순일 경우 시간측정이 무의미 할 정도로 오래 걸렸다.(1억개의 배열 기준)
물론 퀵솔트의 원리를 알고 최악의 경우 O(n^2)인 것을 생각해보면 당연하다고 할 수 있으나 그래도 기대했던 만큼의 속도가 나오지 않았다.
stl의 qsort는 quicksort만으로 이루어진 것은 아닌 듯 하다.
원리
1. 피벗(pivot)이라는 값을 기준으로 더 큰 수는 pivot의 오른쪽 작은 값은 왼쪽으로 정렬시킨다.
2. 정렬이 완료되었으면 피벗을 기준으로 두개의 배열로 나눈다.
3. 나누어진 배열을 다시 1번 부터 재귀적으로 반복한다.
특징
1. 랜덤배열에서 빠른 정렬 속도를 보인다.
2. 피벗(pivot)을 선정하는 방법에 따라 속도가 달라진다.
3. 순열이나 역순의 경우 매우 느린 속도를 보인다.
4. 재귀함수 기반으로 구현시 복잡하게 생각될 수 있다.
연산시간
1. 평균적인 경우(랜덤) : O(n log n)
2. 최악의 경우 : 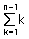 = n(n-1) / 2
= n(n-1) / 2
3. O표기법으로는 O(n^2)이 된다.
코드
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 | // QUICKSORT_ver1 void q_sort(int numbers[], int left, int right) { int pivot, l_hold, r_hold; l_hold = left; r_hold = right; pivot = numbers[left]; // 가장 왼쪽원소를 피봇으로 선택 while (left < right) { // 값이 선택한 피봇과 같거나 크다면, 이동할 필요가 없다 while ((numbers[right] >= pivot) && (left < right)) right --; // 그렇지 않고 값이 피봇보다 작다면, // left 위치에 현재 값을 넣는다. if (left != right) { numbers[left] = numbers[right]; } // left부터 right까지 값을 읽어들이면서 // 피봇보다 큰 값이 있다면, left값을 right로 이동한다. while ((numbers[left] <= pivot) && (left < right)) left ++; if (left != right) { numbers[right] = numbers[left]; right --; } } // 모든 스캔이 끝났다면, 피봇값을 현재 left위치에 입력한다. // 이제 피봇을 기준으로 왼쪽에는 피봇보다 작거나 같은 값만 남았다. numbers[left] = pivot; pivot = left; left = l_hold; right = r_hold; // 재귀호출을 수행한다. if (left < pivot) q_sort(numbers, left, pivot - 1); if (right > pivot) q_sort(numbers, pivot+1, right); } void QuickSort(int numbers[], int array_size) { q_sort(numbers, 0, array_size -1); } int const MAX = 5; int g_arr[MAX] = {0, }; int main() { printf("========정렬전========\n"); //AscendingNumber(g_arr, MAX); // 순열 배열 생성 //DescendingNumber(g_arr, MAX); // 역순 배열 생성 RandomNumber(g_arr, MAX); // 랜덤 배열 생성 PrintNumber(g_arr, MAX); // 배열 출력 printf("\n"); clock_t start = clock(); // 시작 시간 QuickSort(g_arr, MAX); // ShellSort clock_t end = clock(); // 끝 시간 printf("========정렬후========\n"); PrintNumber(g_arr, MAX); // 배열 출력 printf("\nTime : %f\n", ((double)(end-start)) / CLOCKS_PER_SEC); } | cs |
결과
요소 수 : 100,000 100,000,000
랜덤 배열 : 0.017 23
역순 배열 : 12.89 너무 오래걸려서 측정 불가
순열 배열 : 13.21 너무 오래걸려서 측정 불가
결론
[QuickSort_ver1]의 경우 일반적인 방법으로 pivot설정을 가장 왼쪽 요소로 하였다.
시간측정에서 보여지듯이 랜덤배열의 경우 매우 빠른 속도를 보여주지만 순차배열이나 역순배열의 경우 매우 오랜 시간이 걸렸다.
그 이유는 이후에 [피벗설정에 따른 퀵정렬의 속도] 같은 포스트를 통해 이야기 하도록 하겠다.
| 피벗설정에 따른 퀵정렬의 속도 (0) | 2016.01.18 |
|---|---|
| 자동적에이전트 - Seek (0) | 2016.01.17 |
| ShellSort (0) | 2016.01.05 |
| InsertionSort (0) | 2016.01.03 |
| BubbleSort (0) | 2016.01.02 |
ShellSort 는 뭐라하지.. 조개껍질?? 은 아니고 창안자인 도널드 셸을 따서 이름 지었다고 한다.
원리
1. [InsertionSort]와 마찬가지로 현재요소의 제 자리를 찾는 과정이 필요하다.
2. 현재요소( current )가 현재요소 - H( current - H ) 보다 작다면 교환이 일어난다.(H는 H-Sequence)
특징
1. InsertionSort의 최대 장점인 거의 정렬된 배열의 경우 빠르다는 것을 잘 살린 알고리즘이다.
2. for문을 총 3중으로 사용하기 때문에 언뜻보면 O(n^3)으로 볼수 있다. 하지만 일정 Interval을 기준으로 jump하며 반복한다.
3. H-Sequence(= Interval)라고하는 개념을 통해 분할정렬한다.
4. 매우 먼 거리의 요소들을 한번에 가까운 거리로 옮기면서 정렬하기 때문에 교환이 적게 일어난다.
연산시간
1. 최악의 경우 : = n(n-1) / 2
2. O표기법으로는 O(n^2)이 된다.
코드
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 | //SHELLSORT void insertionSort(int* array, int size, int interval) { for (int i = interval; i < size; i++) // i == (1 ~ size) { int temp = array[i]; // 현재값 저장 int tempidx = i; // 현재 인덱스 저장 for (int j = i; 0 <= (j - interval) && temp < array[j - interval]; j -= interval) { // j == (i ~ 0) array[j] = array[j - interval]; // (j) < (j - interval)이면 교환 tempidx = j - interval; } array[tempidx] = temp; // 값 대입 } } void ShellSort(int* array, int size) { for (int h = size; 1 <= h; h /= 2) { insertionSort(array, size, h); // h값을 인자로 넘긴다. } } int const MAX = 5; // Max 값 int g_arr[MAX] = {0, }; // 배열 초기화 int main() { printf("========정렬전========\n"); //AscendingNumber(g_arr, MAX); // 순열 배열 생성 //DescendingNumber(g_arr, MAX); // 역순 배열 생성 RandomNumber(g_arr, MAX); // 랜덤 배열 생성 PrintNumber(g_arr, MAX); // 배열 출력 printf("\n"); clock_t start = clock(); // 시작 시간 ShellSort(g_arr, MAX); // ShellSort clock_t end = clock(); // 끝 시간 printf("========정렬후========\n"); PrintNumber(g_arr, MAX); // 배열 출력 printf("\nTime : %f\n", ((double)(end-start)) / CLOCKS_PER_SEC); } | cs |
결과
요소 수 : 100,000 100,000,000
랜덤 배열 : 0.036 105
역순 배열 : 0.012 17
순열 배열 : 0.0074 13.6
결론
InsertionSort를 변형하여 구현하였다.
구현하면서 느낀점은 InsertionSort의 단점을 상당부분 보안한 알고리즘이라는 것이다.(한번에 많은 이동을 한다는 점에서)
위의 코드와 결과를 보면 알수 있듯이, 구현은 간단하지만 성능은 무시할 수 없는 알고리즘이다.
특히 역순이나 순열의 경우 QuickSort보다 빠른 속도를 보였다.
적절한 상황에 사용하면 좋은 정렬알고리즘이다.
| 자동적에이전트 - Seek (0) | 2016.01.17 |
|---|---|
| QuickSort (0) | 2016.01.07 |
| InsertionSort (0) | 2016.01.03 |
| BubbleSort (0) | 2016.01.02 |
| SelectionSort (0) | 2016.01.02 |
셋째는 InsertionSort, 삽입 정렬이다.
원리
1. 0부터 끝요소까지 반복한다.( current < N )
2. 현재요소의 제 자리를 찾는 과정이 필요하다.
3. 현재요소( current )가 현재요소 - 1( current - 1 ) 보다 작다면 교환이 일어난다.
특징
1. 많은 교환 횟수를 가진다.
2. 이미 정렬되어진 배열의 경우 n - 1번의 비교연산만 수행할 뿐 더 이상의 교환이나 비교연산이 일어나지 않아 빠르다.
연산시간
1. 최선의 경우 : N - 1번
2. 최악의 경우 : = n(n-1) / 2
3. 처음에는 1번 비교하며 N-1번 비교까지 반복한다.
O표기법으로는 O(n^2)이 된다.
코드
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | //INSERTIONSORT void InsertionSort(int* array, int size) { for(int i = 1 ;i < size ;i++ ) // i == (1 ~ size) { int temp = array[i]; // 현재값 저장 int tempidx = i; // 현재 인덱스 저장 for(int j = i ;0 <= (j - 1) && temp < array[j - 1] ;j-- ) // j == (i ~ 0) { // (j) < (j - 1)이면 교환 array[j] = array[j-1]; tempidx = j-1; } array[tempidx] = temp; // 값 대입 } } int const MAX = 5; // Max 값 int g_arr[MAX] = { 0, }; // 배열 초기화 int main() { printf("========정렬전========\n"); //AscendingNumber(g_arr, MAX); // 순열 배열 생성 //DescendingNumber(g_arr, MAX); // 역순 배열 생성 RandomNumber(g_arr, MAX); // 랜덤 배열 생성 PrintNumber(g_arr, MAX); // 배열 출력 printf("\n"); clock_t start = clock(); // 시작 시간 InsertionSort(g_arr, MAX); // InsertionSort clock_t end = clock(); // 끝 시간 printf("========정렬후========\n"); PrintNumber(g_arr, MAX); // 배열 출력 printf("\nTime : %f\n", ((double)(end - start)) / CLOCKS_PER_SEC); } | cs |
결과
랜덤 배열 : 10.60
역순 배열 : 18.70
순열 배열 : 0.00056
결론
이미 정렬이 되어 있는경우 비교를 한번만 한다는 점이 인상적이다. ( 다른 정렬의 경우 교환은 안일어나지만 전체적인 비교는 일어난다. )
이점을 이용하면 좋은 알고리즘을 구현할 수 있을 것 같다.
| QuickSort (0) | 2016.01.07 |
|---|---|
| ShellSort (0) | 2016.01.05 |
| BubbleSort (0) | 2016.01.02 |
| SelectionSort (0) | 2016.01.02 |
| Sort Algorithm (0) | 2015.12.28 |
둘째는 BubbleSort, 버블 정렬이다.
원리
1. 0부터 끝요소까지 반복한다.( current < N )
2. 현재요소( current )와 다음 요소 ( current + 1 )를 비교하여 다음 요소가 더 작으면 교환이 일어난다.
3. 가장 뒤부터 정렬이 일어난다.
특징
1. 많은 횟수를 비교, 교환 하기 때문에 속도가 느리다.
2. pass. 1에서 교환이 일어나지 않을 경우 이미 정렬되어 있는 배열이지만 이것을 확인하지 못하고 정렬을 계속 시도한다.
연산시간
1. 처음에는 N-1번 비교하여 가장 큰 수를 맨뒤로 밀어낸다.
2. 그렇게 [ (N - 2) + (N - 3) + (N - 4) + ... + 1 ] 만큼 비교 및 교환을 수행한다.
3. 식으로 나타내면 = n(n-1) / 2 이며 O표기법으로는 O(n^2)이 된다.
코드
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | //BUBBLESORT void BubbleSort(int* array, int size) { for(int i = 0 ;i < size ;i++) // i == (0 ~ size) { for(int j = 0 ;j < (size - 1) - i ;j++ ){ // j == (0 ~ (size - 1) - i) if(array[j] > array[j+1]) // (j) > (j + 1) 이면 교환 { int temp = array[j]; array[j] = array[j + 1]; array[j + 1] = temp; } } } } int const MAX = 5; // Max 값 int g_arr[MAX] = { 0, }; // 배열 초기화 int main() { printf("========정렬전========\n"); //AscendingNumber(g_arr, MAX); // 순열 배열 생성 //DescendingNumber(g_arr, MAX); // 역순 배열 생성 RandomNumber(g_arr, MAX); // 랜덤 배열 생성 PrintNumber(g_arr, MAX); // 배열 출력 printf("\n"); clock_t start = clock(); // 시작 시간 BubbleSort(g_arr, MAX); // BubbleSort clock_t end = clock(); // 끝 시간 printf("========정렬후========\n"); PrintNumber(g_arr, MAX); // 배열 출력 printf("\nTime : %f\n", ((double)(end - start)) / CLOCKS_PER_SEC); } | cs |
결과
랜덤 배열 : 33.80
역순 배열 : 22.30
순열 배열 : 17.60
결론
버블정렬은 구현하기가 가장 쉬웠던 것 같다.
하지만 이미 정렬된 배열에 대해서 알지 못하고 모두 비교해보기 때문에 적절한 대처방안이 필요할 것 같다. 대처 방안은 언젠가 추가할 것이다.
역시 O(n^2)의 알고리즘 답게 요소가 많아질 수록 응답 시간이 길어졌다.
| ShellSort (0) | 2016.01.05 |
|---|---|
| InsertionSort (0) | 2016.01.03 |
| SelectionSort (0) | 2016.01.02 |
| Sort Algorithm (0) | 2015.12.28 |
| JUMPGAME_알고리즘 (0) | 2015.12.28 |
첫째는 SelectionSort, 선택 정렬이다.
원리
1. 0부터 끝요소까지 반복한다.( current < N )
2. 현재요소( current )와 나머지 요소 중 가장 작은 값을 비교하여 더 작다면 교환이 일어난다.
특징
1. 가장 작은 값을 찾는 과정에서 비교는 여러번 일어나지만 실제로 교환은 한번만 일어 나므로 범위가 작을경우 유리하다.
2. 데이터양이 큰 경우 매번 작은 값을 찾기 때문에 매우 느리다.
연산시간
1. 최선의 경우 비교횟수 : N - 1 ( 정렬이 이미 되어 있는 경우 )
2. 최악의 경우 비교횟수 :N * (N - 1) / 2 ( 역순으로 정렬되어 있는 경우 )
- 처음에는 가장 작은 값을 찾기위해 (N - 1) 번 비교할 것이며 하나씩 정렬 될 때마다 -1 씩 하여 끝에는 1번 비교하게 될 것이다.
즉, 비교횟수는 [ (N - 1) + (N - 2) + (N - 3) ... 1 ]이다.
식으로 나타내면 = n(n-1) / 2 이며 O표기법으로는 O(n^2)이 된다.
코드
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | //SELECTIONSORT void SelectionSort(int* array, int size) { for (int i = 0; i < size; i++) // i == (0 ~ size) { for (int j = i; j < size; j++){ // j == (i ~ size) if (array[i] > array[j]) // (i) > (j) 이면 교환 { int temp = array[i]; array[i] = array[j]; array[j] = temp; } } } } int const MAX = 5; // Max 값 int g_arr[MAX] = { 0, }; // 배열 초기화 int main() { printf("========정렬전========\n"); //AscendingNumber(g_arr, MAX); // 순열 배열 생성 //DescendingNumber(g_arr, MAX); // 역순 배열 생성 RandomNumber(g_arr, MAX); // 랜덤 배열 생성 PrintNumber(g_arr, MAX); // 배열 출력 printf("\n"); clock_t start = clock(); // 시작 시간 SelectionSort(g_arr, MAX); // SelectionSort clock_t end = clock(); // 끝 시간 printf("========정렬후========\n"); PrintNumber(g_arr, MAX); // 배열 출력 printf("\nTime : %f\n", ((double)(end - start)) / CLOCKS_PER_SEC); } | cs |
결과
랜덤 배열 : 31.60
역순 배열 : 19.13
순열 배열 : 13.20
결론
선택정렬은 가장 직관적인 정렬인것 같다. (최소값을 앞에 정렬하는 것이기 때문)
또 10000개 이하 개수에 대해서는 비교하는 것에 비해 교환횟수가 적기 때문에 빠른 속도를 나타낸다.(10000개 기준 0.64초)
하지만 O(n^2)의 알고리즘 답게 요소가 많아질 수록 응답 시간이 길어지는 것이 확실히 보인다.
| InsertionSort (0) | 2016.01.03 |
|---|---|
| BubbleSort (0) | 2016.01.02 |
| Sort Algorithm (0) | 2015.12.28 |
| JUMPGAME_알고리즘 (0) | 2015.12.28 |
| JUMPGAME_문제 (0) | 2015.12.28 |
















